目录
知识库创建时
1. 切片方法
将一个 数据集 / 数据流 分割为更小的片段。
2. 块token数
较小的token时: 模型处理事能够保持较小的工作负载,减小内存开销。但是过小会导致频繁切片和不必要的上下文切换,从而增加开销。在上下文保持方面,过小的切片数据可能会“跨块”,导致信息丢失。
较大的token时: 虽然可以减少切片次数,但是也需要更多的内存开销和计算成本,可能导致内存溢出。如果过大的切片,模型可能无法处理整个上下文信息,导致信息丢失或者需要额外的机制保持上下文信息。
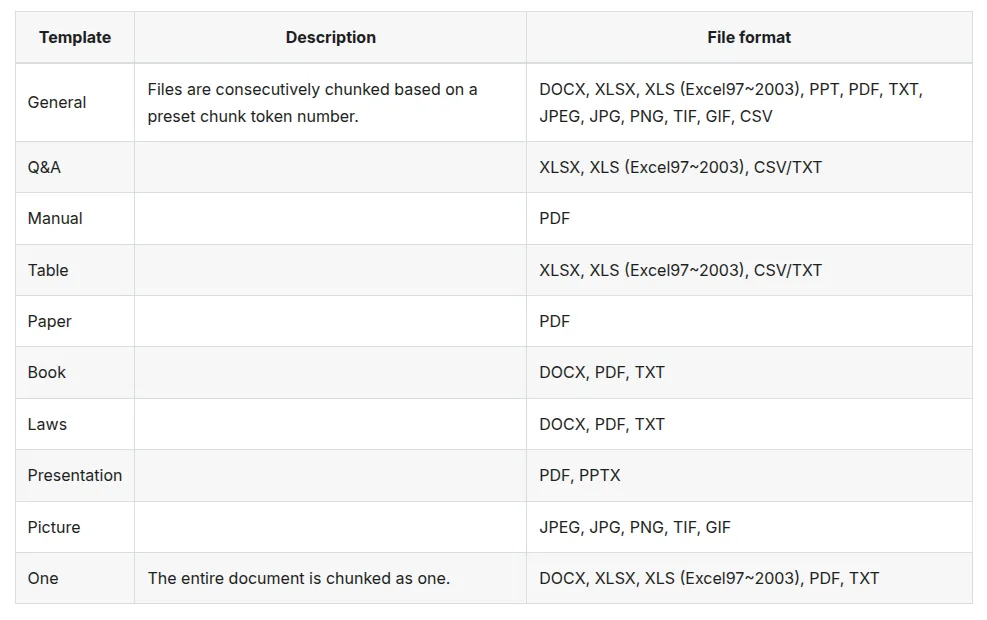
3.页面排名
假设有多个知识库 知识库 A(页面排名得分 5) 知识库 B(页面排名得分 3) 知识库 C(页面排名得分 1) 知识库A会在相关性评分中再加5分,如果相关性得分是最高的,优先返回。 如果知识库A包含更加重要和优先的信息,应当适当调高其页面排名。
4. 自动关键词
在查询时,系统会自动提取与查询相关的关键字,每个块会基于关键词提取N个关键词,有助于更好的匹配查询内容,提高块的相关性得分。 假设你的查询内容是关于“人工智能在医疗中的应用”。系统会自动从相关块中提取出 N 个关键词,如:“人工智能”、“医疗应用”、“诊断”、“算法”等。如果某个块包含这些关键词,并且这些关键词与查询紧密匹配,那么该块的相关性得分会提升,优先返回。
5. 自动问题
在查询时,每个块中提取与查询相关的多个问题,并使用这些问题来提高这个块的相关得分。 假设你正在查询“如何优化深度学习模型的训练”,系统会从相关的块中提取一些与训练优化相关的问题,例如:
“如何选择合适的训练数据?”
“哪些优化算法可以加速模型训练?”
“如何调整学习率以提高训练效果?”
6.标签集
由一个或多个xlsx csv txt文件创建的标签集,包含了用于标记文本块的标签,在配置完标签集以后需要重新解析文档以应用它。数据集中每一个数据块都会和指定标签集比较,根据相似度应用标签。
6.1与自动关键词的区别
标签集是封闭集合是自己写的,需要手动更新,自动关键词数据开放集合,是LLM生成的,基于文本内容动态生成。
Top-N
基于排序标准,从一组数据中选出N个最相关的标签,假设一个文本块有多个标签,系统就可以为文本块分配最具代表的标签。
使用召回增强RAPTOR策略
目的:为了提高RAG能力。 召回(Recall):在信息检索中,召回是指系统能够检索到与查询相关的所有结果的能力。高召回意味着系统能够找到更多相关的结果,尽管它也可能包含一些不相关的结果。 高召回通常意味着系统的覆盖面很广,但可能会牺牲精度(precision)。
区别:传统RAG会从语料库检索出文本块,但是限制了对整体语境的理解。
RAPTOR模型通过 递归嵌入、聚类和总结 长文档的文本块,构建一个 层次化的树形结构,使得模型能够在多个 抽象层次 上进行信息检索。这种方法尤其适合需要复杂推理的任务,能够在检索时整合大量信息,克服传统方法中信息碎片化的不足,从而显著提高 检索效果 和 推理能力。
对于长尾知识①、复杂文档和多步骤推理的任务,RAPTOR 通过这种 递归总结检索 的方式,为 检索增强语言模型 提供了一种有效的提升方案。
rerank模型
在没有启用rerank时,系统使用混合查询(关键词相似度+向量余弦相似度) 启用后,rerank会代替向量相似度。 通常会使用更复杂的机器学习方法(例如,基于深度学习的排序模型),考虑更多的特征(如上下文信息、用户偏好、查询历史等)来对结果进行精细排序。通过这种方式,rerank 模型能够提供更加精准和相关性更高的结果。
加速索引速度(官方)
使用 GPU 来减少嵌入时间。
在知识库的配置页面上,关闭 Use RAPTOR to enhance retrieval (使用 RAPTOR 增强检索)。
提取知识图谱 (GraphRAG) 非常耗时。
在 yor 知识库的配置页面上禁用 Auto-keyword(自动关键词) 和 Auto-question(自动问题),因为两者都依赖于 LLM。
0.17.0 版:如果您的文档是纯文本 PDF,并且不需要 OCR(光学字符识别)、TSR(表结构识别)或 DLA(文档布局分析)等 GPU 密集型过程,您可以在 Document parser (文档解析器) 下拉列表中选择 Naive 而不是 DeepDoc 或其他耗时的大型模型选项。这将大大减少文档解析时间。
①长尾知识:出现频率低,占比小,但是很重要的知识。
本文作者:墨洺的文档
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!